DHS surveys collect data through four main questionnaires. The Household Questionnaire collects data on the characteristics of the household and list all household members. The household roster within this questionnaire captures key characteristics of each household member and is used to select women and men eligible for individual interviews. The Biomarker Questionnaire collects information for each eligible household member on anthropometric measurements and levels of hemoglobin, and records information about samples for biomarker testing. Eligible household members are typically children under age 5, and women and men age 15-49.
Women and men age 15-49 (age range varies for men) are interviewed using the Woman’s Questionnaire and Man’s Questionnaire respectively. The Woman’s Questionnaire, in addition to questions about the woman, contains a birth history that is used to list all children (alive or dead) that the respondent has given birth to, with the child’s sex, date of birth, age, and survival status. The birth history is then the basis for selecting children under certain ages for the maternal health, immunization, child health, and nutrition sections of the questionnaire.
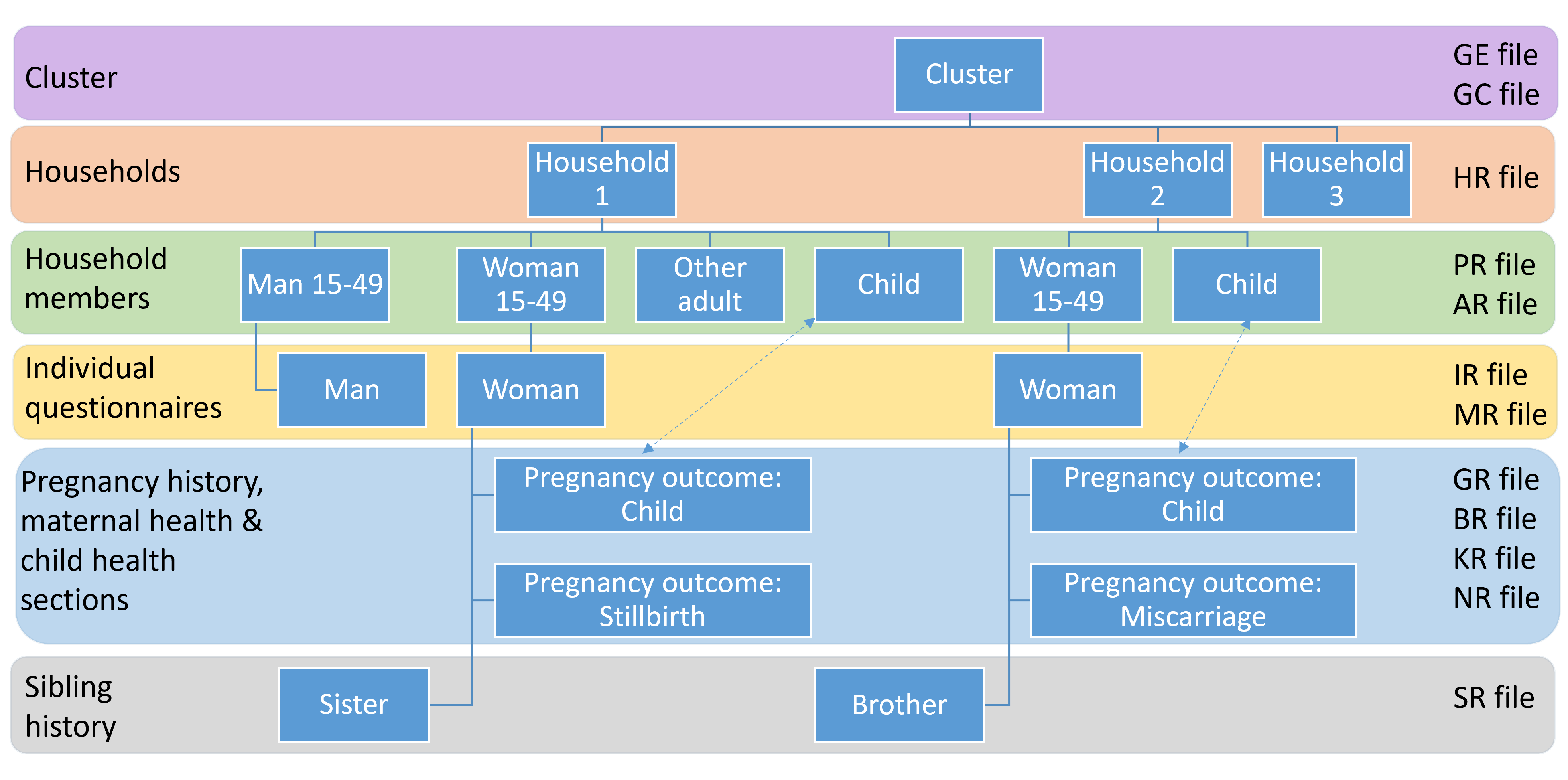
The data from a DHS survey naturally forms a hierarchy of households within a cluster, household members within each household, interviewed women and men as a subset of household members, pregnancies, and children of each interviewed woman, as well as siblings of interviewed women as shown in the example figure below.
Within this hierarchy, data may be collected about the same person in more than one questionnaire. For example, data about women may be collected in the Household Questionnaire, and also in the Woman’s Questionnaire. Similarly for men, some basic characteristics are collected in the Household Questionnaire and in the Man’s Questionnaire. Additionally, data on children may be collected in the Household Questionnaire and in the pregnancy history within a Woman’s Questionnaire – these data can be linked in analysis.
The DHS Program uses a software package, CSPro, to process its surveys. CSPro is developed by the US Bureau of the Census, ICF, and SerPro SA with funding from USAID. CSPro is specifically designed to meet the data processing needs of complex surveys such as DHS, and one of its key features is its ability to handle hierarchical files. CSPro is used in The DHS Program in all steps of data processing with no need for another package or computer language. All steps, from entering/capturing the data to the production of statistics and tables published in DHS final reports, are performed with CSPro. In addition, CSPro provides a mechanism to export data to the statistical packages Stata, SPSS, SAS, and R.
The example above shows that, while a single questionnaire is always completed for each household in the DHS sample, the number of Woman’s Questionnaires or Man’s Questionnaires that will be completed depends on the number of eligible women or men listed in the Household Questionnaire. In other words, for each Household Questionnaire there may be zero or several Woman’s or Man’s Questionnaires.
The hierarchical data file produced in CSPro has a two-level structure reflecting the relationship between the questionnaires; the Household Questionnaire and Biomarker Questionnaire are at level 1 and the Woman’s and Man’s Questionnaires are at level 2. Within each CSPro level, there can be one or more different types of records each containing many variables. For example, records in the household level in a typical DHS file can be single (e.g. household characteristics) or multiple (e.g. household member’s roster). Thus, using the same file, it is possible to work with different units of analysis (households, household members, women, men, and children). This makes the analysis of variables across different units very convenient.
The hierarchical structure defined by CSPro has several advantages and disadvantages. Among the advantages, the following can be highlighted:
· All the data are stored in just one ASCII file. Virtually all packages can read ASCII files.
· Since all the data are stored in the same file, it is easy to maintain the integrity of the data in terms of data structure related to levels and records.
· The data file mirrors the paper questionnaire. Each section in the questionnaire can be defined as a record in the data file and only the information that is needed is present in the file.
The major disadvantage is that only CSPro easily handles hierarchical data. Most analysis software does not support hierarchical data, or at least not simply, so The DHS Program produces a set of exported datasets from the CSPro versions of the DHS recode files with different units of analysis that are convenient for use in statistical software such as Stata, SPSS, SAS, and R.
In the exported files, there is one record for each case. All variables in each case are placed subsequently on the same record. The multiple or repeating records from the hierarchical file are placed one after the other on the record, with the maximum number of occurrences of each section represented in the data file. For example, if a data file collects information on the age of a woman’s children, up to a maximum of 20 children, then there will be 20 records represented in the data file whether or not a woman had the maximum number of children. Each variable in a repeating section is placed immediately after the preceding variable of the same occurrence, such that all variables for occurrence 1 precede all variables for occurrence 2 of a section.
For more information, see the YouTube tutorial video Introduction to DHS Data Structure.
There are four main questionnaires in DHS surveys: a Household Questionnaire, a Biomarker Questionnaire, a Woman’s Questionnaire, and a Man’s Questionnaire. There are also several standardized modules for countries with interest in extra topics. These modules are applied as part of the Household, Biomarker, Woman’s, or Man’s Questionnaires.
Since the very beginning of DHS, a recode file has been a standard part of the survey process. Primarily the recode file was developed to define a standardized file that would facilitate cross-country analysis. Initially it was also to compare data with the World Fertility Surveys (WFS) to study trends. In DHS-I the recode file was defined only for the Woman’s Questionnaire, as the Household Questionnaire was originally just used for the selection of women for interview. Additionally, the use of a Man’s Questionnaire was not part of the original design, and only a few men’s surveys took place in DHS-I. The recode file proved to be very useful and as a result, since DHS-II, a recode file was introduced for the Household and Man’s Questionnaires.
DHS questionnaires have changed extensively since the first phase. For this reason, there is a different recode definition for each DHS phase. However, if a variable is present in one or more phases, that variable has the same meaning in each phase in which it is present. If a question is dropped from one phase to another, the name of the variable used for that question is not reusable. The variable will not be present in the recode of the phase where it was dropped. If a new question is added to the core questionnaire, a new variable will be added to the recode definition.
See https://www.dhsprogram.com/data/Data-Variables-and-Definitions.cfm for a discussion of the benefits of the recode files.
Recode files are created using a hierarchical model in CSPro and later exported to files compatible with Stata, SPSS, SAS, and R for use by analysts. The DHS Recode Manual provides a description of the contents of the recode file, including a brief description of each variable and the applicable base for the variable. The DHS Recode Map provides a simple codebook for the standard DHS recode. The DHS Recode Manual and Map for all phases of DHS can be found at https://www.dhsprogram.com/publications/publication-dhsg4-dhs-questionnaires-and-manuals.cfm.
The DHS Program recode files are exported into several dataset types. Below is a description of the dataset types referred to in the Guide to DHS Statistics, together with the unit of analysis (or case) for each dataset:
Unit of analysis: Household
Includes household characteristics, the household roster, and biomarkers rosters as repeating sets of variables. This dataset is used for calculation of household level indicators such as water and sanitation (see Chapter 2).
Unit of analysis: Household member
Includes characteristics of household members including age, sex, marital status, education, as well as biomarker measurement information. The dataset includes both de facto and de jure household members. It also includes the characteristics of the households where the individual lives or was visiting. This dataset is used for analysis of education of household members (Chapter 2) and of anthropometry and anemia in children under age 5 (Chapter 11).
Unit of analysis: De facto woman interviewed
Contains all the data collected in the Woman’s Questionnaire for de facto women plus some variables from the Household Questionnaire. Up to 20 births in the birth history (see also BR file), and up to 6 children under age 5 (see also KR file), for whom pregnancy and postnatal care as well as immunization, health and nutrition data were collected, can be found as repeated variables in this file. This dataset is used for most woman-level analysis including marriage and sexual activity (Chapter 4), fertility and fertility preferences (Chapters 5 and 6), family planning (Chapter 7), anthropometry and anemia in women (Chapter 11), malaria prevention for women (Chapter 12), HIV/AIDS (Chapters 13 and 14), women’s empowerment (Chapter 15), and domestic violence (Chapter 17).
Unit of analysis: Birth
Contains the full birth history of all women interviewed, including information on pregnancy and postnatal care as well as immunization, health and nutrition data for children born in the last 5 years. Data for the mother of each of these children are also included. This dataset is used for fertility (Chapter 5) and mortality (Chapter 8) analysis.
Unit of analysis: Pregnancy outcome
Contains the full pregnancy history of all women interviewed, including information on type of pregnancy outcome, and pregnancy and postnatal care for pregnancies ending in the 3 years preceding the survey. Data for the mother of each of these pregnancy outcomes are also included.
Unit of analysis: Child under age 5 born to a woman interviewed
Contains information related to the child's pregnancy and postnatal care and immunization, health and nutrition data. The data for the mother of each of these children is also included. This dataset is used to look at child health indicators such as immunization coverage, vitamin A supplementation, recent occurrences of diarrhea, fever, and cough for young children and treatment of childhood diseases (Chapter 10), nutrition of young children (Chapter 11), and malaria prevention and treatment (Chapter 12).
Unit of analysis: Pregnancy outcome in the 3 years preceding the survey to a woman interviewed
Contains the information related to pregnancy and postnatal care for pregnancy outcomes in the 3 years preceding the survey. This dataset is used for analysis of maternal healthcare (Chapter 9).
Unit of analysis: De facto man interviewed
Contains all data collected in the Man’s Questionnaire de facto men plus some variables from the Household Questionnaire. This dataset is used for most man-level analysis including marriage and sexual activity (Chapter 4), fertility preferences (Chapters 6), and HIV/AIDS (Chapters 13 and 14).
Unit of analysis: Married woman and man
Contains data for married or living together women and men who both declared that they are married (living together) to each other and with completed individual interviews. This dataset is the result of linking the IR and MR files, based on whom they both declared as partners. In polygynous societies a man’s data may be linked to more than one woman’s data. This dataset is used for analysis of couples, principally related to HIV (Chapters 13 and 14).
Unit of analysis: Sibling
Contains data for each sibling of the interviewed woman including their sex, survival status, age (if alive), age at death and years since death (if deceased), and for female siblings age 12 and above information on whether the death was pregnancy-related. This dataset is used for analysis of adult and maternal mortality (Chapter 16).
Unit of analysis: Person tested for HIV
Contains the result of lab testing for HIV from blood samples provided by women and men, together with a separate weight variable for use when analyzing HIV test results. This dataset is used for analysis of HIV prevalence (Chapter 14).
The DHS Program has also prepared two geographic datasets that data analysts can use with DHS data:
Unit of analysis: Cluster
The geographic datasets (also known as GPS data) contain a single record per cluster in which the survey was conducted and provide the latitude, longitude, and elevation for the survey cluster, for use in Geographic Information Systems (GIS). Questions concerning the geographic data are addressed on the Geographic Data forum within the DHS User Forum.
Unit of analysis: Cluster
The geospatial covariate datasets link survey cluster locations to ancillary data, known as covariates, that contain data on topics including agriculture, environment, health, infrastructure, and population factors. This allows individuals with limited GIS experience to conduct geospatial statistical analysis without having to manually source and link these covariates to cluster locations. These covariates are extracted from freely available global datasets. See the Spatial Data Repository’s Covariates webpage and Methodology webpage for more information. Python code for the extraction of covariates from other sources for DHS clusters can be found on GitHub.
In addition to the contextual variables that can be included in analysis from the geospatial covariates, interviewers can also have an effect on the responses to certain survey questions. To permit analysis of interviewer effects on survey responses analysts can also use the characteristics of the fieldworkers.
Unit of analysis: Fieldworker
Contains the basic characteristics of each fieldworker who participated in the survey, including their age, sex, marital status, level of education, region of residence, languages, and prior experience with DHS or other surveys. Data from the fieldworker’s dataset may be linked to the survey responses using the interviewer, supervisor, field editor, or biomarker specialists IDs.
Additional dataset types also exist, and when using older datasets, two of these are of particular relevance:
Unit of analysis: Household
Contains the wealth score and quintiles for surveys prior to the late 1990’s. Wealth Index analysis was introduced to The DHS Program around the end of the 1990's. When the decision was made to include the wealth index as part of DHS, standard variables were added to the recode definition for both the household and individual datasets (hv270 and hv271 for households; v190 and v191 for women; and mv190 and mv191 for men). For surveys conducted prior to the change in the recode file definition a file was created containing the score and the quintile variables. Wealth index files were created for all DHS surveys except surveys carried out as part of DHS-I. This dataset can be linked to any of the datasets described above.
Unit of analysis: Children under age 5
In 2006 new child growth standards were introduced by WHO. Prior to this time, The DHS Program used the NCHS/CDC/WHO reference. After the adoption of the new WHO standards, standard recode variables hv70 to hv73 and hw70 to hw73 were added to the recode definition to store the z-scores based on the new WHO child growth definition. All files using the DHS-V, DHS-VI or DHS-7 recode structure have these variables. For surveys prior to DHS-V, a file was created containing the z-scores based on the new standard. In early DHS phases only children of interviewed women were measured. Starting with DHS-III onwards all children under five listed in households interviewed have been measured. This dataset can be linked to the household members (PR), the children under five (KR) or the births (BR) datasets described above if height and weight was taken for children in the households. The file can only be linked to the children under five (KR) or birth (BR) dataset when only children of interviewed women were measured for early DHS phases.
Additional information about datasets can be found in The DHS Program YouTube video on DHS Dataset Types in 60 Seconds and on The DHS Program at https://www.dhsprogram.com/data/Dataset-Types.cfm.
Survey datasets are distributed as compressed .zip files. Each zip file contains a dataset and related documentation files. The naming of the zip files and their contents follows the DHS file naming convention: CCDDVVFF[DS].ZIP
Code Description:
· CC: Country Code
· DD: Dataset Type. See File types above.
· VV: Dataset Version. First character - DHS Phase, second character - Release version.
· FF: File Format. DT - Stata, SV - SPSS, SD - SAS, FL - Flat, no file format – Hierarchical.
· DS: Data Structure. SPA only: SR - SPA Recode, SP - SPA Raw.
For example, UGIR7ADT.ZIP contains the Stata version of the Individual Women’s Recode dataset for the Uganda 2016 DHS conducted as part of DHS-7.
The DHS file naming convention is described in detail at https://www.dhsprogram.com/data/File-Types-and-Names.cfm.
The list of datasets available for each survey can be found on The DHS Program website at https://www.dhsprogram.com/data/available-datasets.cfm, or through The DHS Program API using the datasets call, e.g. https://api.dhsprogram.com/rest/dhs/datasets?f=html&perpage=1000. The API call can be filtered by country, survey, survey type, file format, or dataset type (file type). See https://api.dhsprogram.com/#/api-datasets.cfm for more information on using the API datasets call.
Variables in the recode file begin with one or two letters followed by one to four (typically three) digits and in some cases followed by a letter. Following is a list describing the general variable name conventions.
hv0xx Basic characteristics of the household interview (hhid,hv000-hv048)
hv8xx Time of household interview and date of biomarker visit (hv801-hv807a)
hv1xx Characteristics of household members (hvidx,hv101-hv140)
hv2xx Characteristics of the household (hv201-hv271a)
haxx Anthropometry, anemia and biomarkers for women (ha0-ha73)
hbxx Anthropometry, anemia and biomarkers for men (hb0-hb73)
hcxx Anthropometry, anemia and biomarkers for children (hc0-hc73)
hmlxx Mosquito net characteristics and use (hmlidx,hml3-hml11,hml21-hml24,hmla-hmle)
Mosquito net use by household members (hml12-20), and malaria test results (hml30-hml40)
hdisx Disability (idxdis,hdis1-hdis9)
hclx Child labor (hchline,hchl2a-hchl14,hchlwgt)
hcdix Child discipline (hcdi2-hcdi4,hcdwgt)
haix Accidents and injuries (haiidx,hai1-hai13z)
hexx Health expenditure (idxhex,hex1-hex5), inpatient health expenditures (hex20-hex38), outpatient health expenditures (hex70-hex79,hexowgt)
hfsx Food insecurity experience scale (hf1-hfs8,hfs_mod,hfs_sev)
shxxx Survey-specific household or household member characteristics
v0xx Basic characteristics of the women’s interview (caseid,v000-v048)
v1xx Woman’s characteristics (v101-v191a)
bxx Birth history (bidx,bidxp,bord,b1-b21)
pxx Pregnancy history (pidx,pidxb,pord,p0-p32)
v2xx Reproduction (v201-v249)
v3xx Contraception (v301-v3a14)
mxx Maternal health, pregnancy, postnatal care and breastfeeding (midx,midxp,m1-m82,ml0-ml2,mnb1-mnb12,mh3a-mh25)
v4xx Anthropometry and anemia of interviewed women, breastfeeding, and feeding of youngest child living with mother (v401-v486)
hxx Immunization and child health (hidx,h0-h80g)
hwxx Anthropometry for children of interviewed women (hwidx,hw1-hw73)
v5xx Marriage and sexual exposure (v501-v544)
v6xx Fertility preferences (v602-v636)
v7xx Husband’s characteristics, women’s work, women’s empowerment (v701-v746)
HIV/AIDS knowledge, attitudes and practices, and sexually transmitted infections (v750-v792y)
v8xx Interview characteristics (v801-v815c)
HIV related practices, sexual activity (v820-v867g)
vcal Reproductive/contraceptive calendar
mmxx Adult and maternal mortality (mmidx,mm1-mm16)
mlxx Malaria-related child health (idxml,ml0-ml25a)
Social behavioral change communication (ml501-ml514)
dxxx Domestic violence (d005,d100-d130c)
gxxx Female genital cutting (g100-g119,gidx,g121-124)
ecdxx Early childhood development index (idxecd,idxecdp,ecd21-ecd40)
chdxx Chronic diseases (chd01-chd33)
mthxx Mental health (mth1-mth24)
fisxx Fistula (fi1-fi12)
sxxx Women’s survey-specific
mv0xx Basic characteristics of the men’s interview (mcaseid,mv000-mv048)
mv8xx Interview characteristics (mv801-mv803)
mv1xx Man’s characteristics (mv101-mv191a)
mv2xx Reproduction (mv201-mv253)
mv3xx Contraception (mv301-mv3b25b)
mv4xx Smoking, tuberculosis and other adult health issues (mv463a-mv485b)
mv5xx Marriage and sexual exposure (mv501-mv541)
mv6xx Fertility preferences (mv602-mv634d)
mv7xx Employment (mv714-mv747b)
HIV/AIDS knowledge, attitudes and practices, and sexually transmitted infections (mv750-mv793b,mv820-mv867g)
mgxxx Female genital cutting (mg100-mg119)
mchdxx Chronic diseases (mchd01-mchd33)
mmthxx Mental health (mmth1-mmth24)
smxxx Men’s survey-specific
hivxx HIV test results
Recode variable names are used consistently across DHS, AIS, and MIS surveys to facilitate analysis regardless of type of survey.
In DHS datasets there are several special values that have particular codes. Two of them are very important – not applicable and missing. The DHS Program treats these two differently although some software treat them as the same.
· “Not applicable” is defined as when a question is not supposed to be asked due to the flow of the questionnaire. For example question 227 in the Woman’s Questionnaire “How many months pregnant are you?” is not applicable if the answer to the preceding question 226 “Are you pregnant now?” is No or Unsure. Question 227 would be left blank in the questionnaire in this case.
· “Missing” is defined as a variable that should have a response, but because of interviewer error the question was not asked. For example, question 227 “How many months pregnant are you?” should be answered if a woman responded Yes to question 226 “Are you pregnant now?” If the interviewer incorrectly left the question blank, then a code is required to recognize that. The general rule for DHS data processing is that answers should not be made up, and so a “missing value” will be assigned. The data will be kept as missing in the data file and no imputation for this kind of question will be done. Missing values in general are codes 9, 99, 999, 9999, etc. depending on the number of digits used for the variable.
There are important differences in how “not applicable” and “missing” are handled in each of the statistical software:
· In Stata, in most datasets both not applicable and missing values have been converted to Stata’s missing value (.). In some datasets though the codes remain as 9, 99, 999 or 9999. Starting in DHS-8, missing values will be (.a) and not applicable values will be (.).
· In SPSS, not applicable values are converted to system missing, while the missing values are converted to user missing.
· In SAS, as in Stata, both not applicable and missing values have been converted to SAS’ missing value (.)
The distinction between “not applicable” and “missing” can be important for matching results from DHS reports. In general, the denominators for most indicators in DHS reports exclude the “not applicable” cases but include the “missing” cases. Careful attention to the selection of the denominator and then ensuring that “missing” values are correctly treated is important for ensuring that results match those published in DHS survey reports.
There are some important background variables where the “missing” code is not accepted, including:
· Geographical variables such as type of place of residence (urban/rural) (hv025, v025, mv025, v102, mv102), regions (hv024, v024, v101, mv101), and any other variable whose value can be established by the sample design
· Level of education for women and men in the individual questionnaire (v106, mv106)
· Current use of contraception for women (v312)
· Current marital status of women and men (v501, mv501)
· Variables related to the woman’s birth history (v201 to v210, b0, b4, b5, b9).
Note though that in earliest phases of DHS it is possible that some of these variables may have “missing” values.
In addition to “not applicable” and “missing” values there are often other special values recorded in the datasets. Codes 8, 98, 998, 9998 are assigned to “don’t know” responses. These codes are normally pre-coded in the questionnaires and are consistently used throughout the recode file.
Another special code used for data editing purposes is code “Inconsistent.” This code is generally used in the secondary editing of data, when a value or code is not plausible, but it is impossible to determine the correct code. For example, dates for vaccinations recorded as having occurred before the birth of the child. The value is not missing but is not possible. The secondary editing team is instructed to first check for clues that could lead to correcting the problem, but if that is not possible, to establish which piece of information is wrong (day, month, or year) and assign the code for “Inconsistent” to that item. Inconsistent codes are 7, 97, 997, 9997 depending on the variable number of digits.
Other special responses may be coded 96 (996, 9996), 95 (995, 9995), 94 (994, 9994), etc. For example, in variable v226 (Time since last period (comp) (months)) code 996 means “Never menstruated”, code 995 means “Before last birth”, and code 994 means “In menopause”. As another example, variable v525 (age at first sex) has codes 99 “Missing”, 98 “Don’t know”, 97 “Inconsistent”, 96 “At first union”, and 0 “Not had sex”.
All of these special codes should be taken into account when analyzing DHS datasets. For example, if they are not excluded to calculate the mean age at first sex, eventually the mean will be inflated by ages 96, 97, 98, and 99. Even code 0 would need to be excluded as it would incorrectly deflate the mean age at first sex.
In general, The DHS Program uses a conservative approach to the calculation of indicators including missing and special values in denominators of most percentages (but not means and medians) and excluding them from the numerators or showing them as separate categories in percent distributions.
DHS Recode files are created through a complex recoding application, converting the raw data as collected in the questionnaires into a standardized recode format for use in analysis. In this process there are a number of different types of variables constructed. For most variables this is a one-to-one conversion, possibly recoding categories (e.g. converting No = 2 in the questionnaire to No = 0 in the recode variable), while for others the creation is more complex. The creation of some types of variables is described below.
In multiple response questions, the question is asked, and the respondent spontaneously begins providing answers. The answers are not read, but the interviewer must classify the response according to the options available for the question. The interviewer keeps probing for other responses until the respondent says that she has no more answers. Question 414 of the Woman’s Questionnaire is a typical example of this type of question:

At the time of data capture, all responses are stored in just one field. However, dealing with combinations of alphabetic codes presents a challenge for analysis purposes, so each response for this type of question is translated into codes 0 = No, 1 = Yes, 9 = Missing, in separate variables in the recode files:
m2a Prenatal care: Doctor
m2b Prenatal care: Nurse/Midwife
m2c Prenatal care: Auxiliary Midwife
m2d Prenatal care: CS Health Specialist
m2e Prenatal care: CS Health Specialist
m2f Prenatal care: CS Health Specialist
m2g Prenatal care: Traditional Birth Attendant
m2h Prenatal care: Village Health Worker
m2i Prenatal care: CS Other Person
m2j Prenatal care: CS Other Person
m2k Prenatal care: Other Response (uncoded)
m2l Prenatal care: CS Other
m2m Prenatal care: CS Other
m2n Prenatal care: No One
(variables in italics are used for survey-specific categories)
In creating these variables there are several conditions taken into consideration with this type of variable:
· If the question was missing, all applicable variables will be assigned the code “missing”.
· If a response category does not exist for a particular survey, the variable will be left blank “not applicable”.
· There are provisions for survey-specific (CS = country-specific) responses that are not part of the standard model questionnaires. For example, some countries include additional categories of health professionals.
In multipart questions the response for the separate parts of the question are usually stored in separate variables in the recode files. For example, question 418 in the Woman’s Questionnaire is as follows:

Each part of the question is treated as a separate variable in the recode file:
m42c During pregnancy: blood pressure taken
m42d During pregnancy: urine sample taken
m42e During pregnancy: blood sample taken
m42f During pregnancy: listen to baby’s heartbeat
m42g During pregnancy: talk about foods to eat
m42h During pregnancy: talk about breastfeeding
m42i During pregnancy: ask about vaginal bleeding
Each variable is coded 0 = No, 1 = Yes, 9 = Missing.
Certain date variables in DHS surveys receive special treatment. As dates are central to the calculation of fertility and mortality rates and the selection of cases for inclusion in other analyses, there is a need for fully specified dates (month and year) for key events. These events are:
· Date of birth of the respondent
· Date of first marriage or union
· Dates of birth of each child
· Date started using current method of contraception
· Date current pregnancy started
· Date of interview
Note that the date of interview is always fully specified and can have no special values.
However, the respondent may not know the exact date of an event, the date (or part of it) may have been left blank by the interviewer, or the date may have been inconsistent with other information. For all of these situations the month and/or year part of the date variables may have either the missing value code or one of the other special codes. As fully specified dates are required for analysis, The DHS Program uses a process of date editing and imputation to impute exact dates (to the month and year) for each of these dates.
The DHS Program date editing and imputation uses a multi-step process:
1) Construct logical ranges using the information reported for the date.
2) Apply isolated constraints to narrow the ranges
3) Apply neighboring constraints to further narrow the ranges
4) Ensure sufficient gap between events, further narrowing ranges
5) Random imputation within final ranges.
The result of these steps is the production of imputed dates for the key dates:
· Date of birth of the respondent (month: v009, year: v010, CMC: v011, flag: v014)
· Date of first marriage or union (month: v507, year: v508, CMC: v509, flag: v510)
· Dates of birth of each child (month: b1, year: b2, CMC: b3, flag: b10)
· Date started using current method of contraception (month: v315, year: v316, CMC: v317, flag: v318)
· Date current pregnancy started (duration of current pregnancy: v214, flag: v223)
· Date of interview (month: v006, year: v007, CMC: v008)
Flag variables indicate the information originally provided as input to the imputation process for the date. Note that although date of current pregnancy started is imputed, the variable included in the recode file is just the duration of pregnancy, calculated by subtracting the imputed date current pregnancy started from date of interview.
Each of these steps is described in more detail in DHS Data Editing and Imputation (Croft, 1991)
https://www.dhsprogram.com/publications/publication-DHSG3-DHS-Questionnaires-and-Manuals.cfm.
For simplicity of calculation dates of key events are presented both as month and year and in terms of Century Month Codes.
Century month codes (CMC) are calculated by taking the difference between the year of an event and 1900, multiplying by 12, and adding the month of the event:
CMC = (Year – 1900) * 12 + Month
January 1900 is CMC, February 1900 is CMC 2, January 1901 is CMC 13, and December 1999 is CMC 1200. For example, the CMC for August 2018 is:
CMC = (2018 - 1900) * 12 + 8 = 1424
In other words, 1424 months have elapsed between January 1900 and August 2018, inclusive.
Based on CMC it is possible to calculate the month and year using the following formulas:
Year = int( ( CMC - 1 )/12 ) + 1900 [int(x) is the integer part of x]
Month = CMC - ( ( Year - 1900 ) * 12 )
The year 1900 was chosen as the reference date because all of the DHS relevant events occurred during the twentieth or twenty-first centuries. Century Month Codes was also used in the World Fertility Surveys (https://wfs.dhsprogram.com/) that were the precursor to The DHS Program, and all dates in those surveys (conducted from 1976 to 1984) were in the 20th century, hence the name.
Century month codes are particularly important to check consistency of dates, to calculate intervals between events, and in the imputation of dates when the information for an event is missing or partially complete. The main DHS events with their corresponding recode variable names are given above.
Let us see the events for a married, sterilized respondent with three births and with event dates that occurred as shown in the following figure. If a horizontal line is drawn from the woman’s date of birth to the date of interview, all the events can be depicted in the line.
|
Variables |
v011 |
v509 |
b3_1 |
b3_2 |
b3_3 |
v317 |
v008 |
|
Dates |
04/1992 |
10/2011 |
07/2013 |
10/2014 |
11/2016 |
04/2017 |
08/2018 |
|
CMC |
1108 |
1342 |
1363 |
1378 |
1403 |
1408 |
1424 |
|
Event |
Date of birth |
Date of marriage |
Date of birth of first child |
Date of birth of second child |
Date of birth of third child |
Date of sterilization |
Date of interview |
DHS uses century month codes extensively during the process of editing and imputing data. The advantages of the approach include the following:
· When checking for consistency, use of the century month codes makes it easy to check not only that the events occurred in chronological order, but also that there should be a minimum interval between them. For example, b3_2 - b3_1 should be greater or equal to 9 months (the expected duration of a pregnancy).
· For imputation purposes, if information were missing between two events, the random imputation would be quite reasonable. For example, if date of birth for the second child is unknown, that birth should have occurred between the first birth plus nine months, and nine months before the third birth. The lower and upper limits for a random number generator are plausible, e.g.:
random (b3_1 + 9, b3_3 - 9) = random (1372, 1394)
The use of CMC in analysis facilitates the calculation of intervals or ages at different events. Throughout The DHS Program analysis programs, instructions such as those shown below are very common:
· Respondent’s age = int( (v008 - v011)/12 ) (1424 - 1108)/12 = 26 years
· Age at first birth = int( (b3_1 - v011)/12 ) (1363 - 1108)/12 = 21 years
· Age at sterilization = int( (v317 - v011)/12 ) (1408 - 1108)/12 = 25 years
· Age of last child in months = v008 - b3_3 1424 - 1403 = 11 months
· Interval between birth 1 and 2 = b3_2 - b3_1 1378 - 1363 = 15 months
· Months since sterilization = v008 - v317 1424 - 1408 = 16 months
DHS recommends that analysts use the century month code variables when dealing with intervals or ages at different events.
The Century Month Code works well for most DHS analyses, but there are three countries that use non-western calendars. To date these countries are:
• Ethiopia: The Ethiopian calendar is 7-8 years behind the Gregorian (Western) calendar, and the Ethiopian year starts around September 11th or 12th of each year (exact day varies). 1st July 2017 is 24 Sane (the 10th month) 2009 in the Ethiopian calendar. The Ethiopian calendar consists of 12 months of 30 days, plus one month of 5 days (or 6 days in a leap year). The century month codes in the dataset are all based on the Ethiopian calendar, but “squeezing” the 13th month into a 12-month calendar. The reference date for surveys in Ethiopia is 1 Mäskäräm 1900 in the Ethiopian Calendar, which is September 12, 1907, in the Gregorian calendar. To approximately adjust dates to the Gregorian calendar add 92 months to the CMC.
• Nepal: The Nepali calendar is 56-57 years ahead of the Gregorian (Western) calendar, and the Nepali year starts around mid-April of each year (exact day varies). 1st July 2017 is 17 Ashad (the 3rd month) 2074 in the Nepali calendar. The Nepali calendar is made up of 12 months of between 28 and 32 days, and the number of days in a month can vary from year to year. The century month codes in the dataset are all based on the Nepali calendar. The reference date for surveys in Nepal is 1 Baisakh 1900 in the Nepali Calendar, which is April 16, 1843, in the Gregorian calendar, for all surveys in Nepal except for the Nepal DHS 1996, in which the reference date was 1 Baisakh 2000 in the Nepali Calendar, which is April 14, 1943, in the Gregorian calendar. To approximately adjust dates to the Gregorian calendar subtract 681 months from the CMC, or, in the case of Nepal DHS 1996, add 519 months.
• Afghanistan: The Afghan calendar is 621-622 years behind the Gregorian (Western) calendar, and the Afghan year starts around March 20th or 21st of each year (exact day varies). 1st July 2017 is 10 Saratan (the 4th month) 1396 in the Afghan calendar. The Afghan calendar is made up of 12 months, the first 6 of which have 31 days, the next 5 months have 30 days, and the last month has 29 or 30 days in a leap year. The century month codes in the dataset are all based on the Afghan calendar with 1300 as the base year, rather than 1900. The reference date of surveys in Afghanistan is 1 Hamal 1300, which is March 21, 1921, in the Gregorian calendar. To approximately adjust dates to the Gregorian calendar add 255 months to the CMC.
All calculations with CMCs in these surveys work as they do for any other survey. The exception is any analysis requiring specific years, in which case adjustments must be made to the calculated CMC as described above. It should be noted, however, that these are approximate adjustments as the calendars start in the middle of month and dates of events to the day would be required to calculate exact adjustments.
In DHS-7, The DHS Program introduced the collection of day of birth of children in the birth history in addition to the month and year of birth. Adding day of birth permits calculating the age of children more accurately. Calculating age in months using just month and year of birth and month and year of interview meant that age in months could be off by one month in approximately half of all cases. For many analyses this difference was small and had little effect, but for some analyses this difference could be more meaningful. With the introduction of day of birth, and the need to calculate age of children more accurately, The DHS Program introduced the Century Day Code (CDC). The Century Day Code is the number of days from the beginning of 1900. January 1, 1900, is CDC 1, January 2, 1900, is CDC 2, December 31, 1999, is CDC 36525, and August 1, 2018 is CDC 43313. The Century Day Code is not simple to calculate manually, but it is the same system used in Excel for calculations between dates.
To find the CDC for a date using Excel, enter the date into a field (say A1), and then, in another field (say B1) enter:
=VALUE(A1)
Similarly, to get the date from a CDC value in Excel, use the day(), month() and year() functions in Excel (or simply convert the Numeric cell to a Date cell).
In Stata, the CDC can be calculated using the mdy() function as follows:
gen CDCode = mdy(month, day, year) + 21916
e.g.
gen b18 = mdy(b1, b17, b2) + 21916
The mdy() function uses January 1, 1960, as its base. The 21916 is the offset to use January 1, 1900, as the base (365.25 * 60 + 1).
In SPSS, the CDC can be calculated using the yrmoda() function as follow:
compute CDCode = yrmoda(year, month, day) - (yrmoda(1900, 1, 1) - 1) + 1.
e.g.
compute B18 = yrmoda(B2, B1, B17) - (yrmoda(1900, 1, 1) - 1) + 1.
The yrmoda() function uses October 14, 1582, as its base.
The Century Day Codes are used with the date of birth of children and the date of interview and permit the calculation of age of children accurate to the day (see Age of Children). For some dates of birth of children, the exact date may not be fully specified at the time of data collection. For these dates an imputation process is followed, building on the imputation process for date variables described above, and resulting in the imputation of a century day code for all children in the woman’s birth history.